In Cantonese, there are many cases where there is ambiguity in how a character should be pronounced. Jon tried to make a best guess at what most people would try to say, and put that suggestion into the font. What if it is wrong?
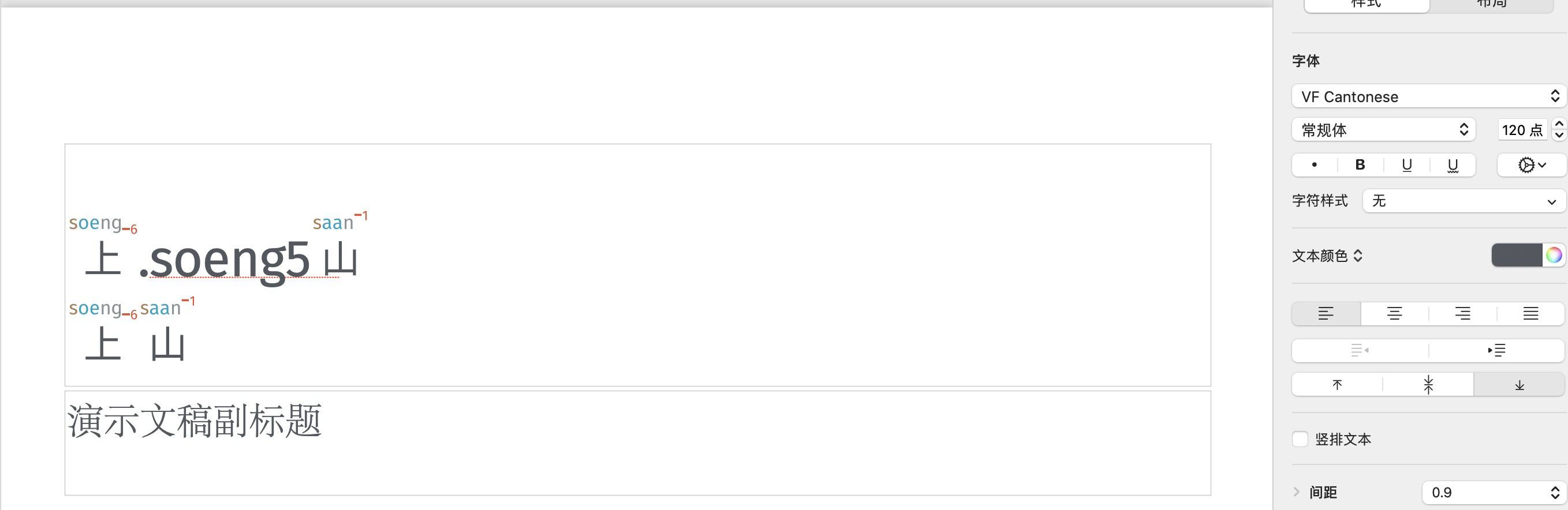
As an example, let’s look at a phrase 小明話佢做晒功課喎, which in version 2.0.21.0 is shown as

with a wo3 assignment for 喎. The phrase then means “But I heard that Ming says he finished all his homework”.
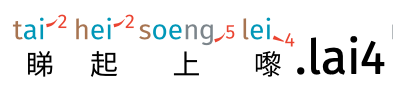
If the same character, 喎, is pronounced as wo5, the phrase means “Ming says he finished all his homework, but I don’t believe it”. What if you want to show this second usage?
To override a reading, append .jyutping after a character.
In this case, if you type .wo5 at end of the sentence, the appearance will then transform:

The sounds available for each character are exhaustive; if you tried a jyutping and it doesn’t work, it is more likely than not that it is not a possible jyutping for that character (e.g., you are trying to override 曰 with jat6, not realizing it is the character for “to speak” instead of “sun 日”.) In the future (probably summer/fall 2024), I’ll provide a web-app for you to query what sounds are available for a given character. In the meantime you can ask me.
Exceptions
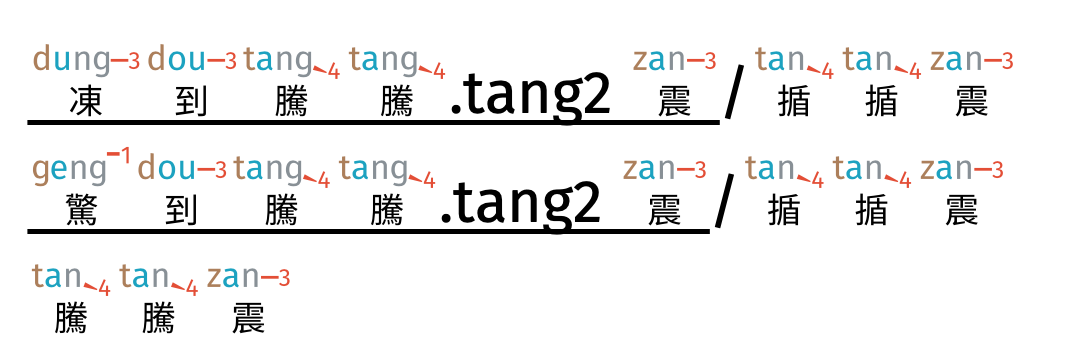
There are cases where you typed the .jyutping and nothing changes. Yikes. Like this:


You’ve added the right jyutping, and bewilderingly it stays as soeng5.
What happens in these cases is that the word 上落 binds very strongly, and the reading there is tone-5. What you can do is instruct the font that 天上 is a concept, and 落雪 is another one. This is done by using a | (pipe/bar; on US keyboards it’s above the return/enter key):

This is called segmentation, and means “breaks this up because of a word boundary”. This process is a standard step in lingustic works for languages that does not use space as a word separator, and is more generally useful than just coercing a pronunciation, as this now provide more information about the text. You can read more about this markup system here: .
Super exceptions
There is a theoretical possibility that you want to split what the font considers as a word, you agree that it is a word, and you are thus philosophically opposed to using the | markup since it would mean it’s not a word. (I know, I know.) In these rare cases, you can use the \ backslash marker, which is intended to mean “break this up forcefully for no stated reason”. Use this sparingly and only when you must.