There are three permissible pronunciations for 褸:

LibreOffice cannot interpret .jyutping syntax. The immediate general workaround is to use a word processor that does support this (e.g., Pages).
In this specific case, users are most likely to use 褸 the same way as you are using; in 2.8, I will change the standalone reading to lau1. That release is likely around mid-July. (I have additionally added (金)褸衣 to the word-list for 2.8, where 褸 takes on lau5.). Thank you for your report.
The future general solution is for me to push forward on the companion app, that provides a copy-to-image option from a web interface. There is a technical proof-of-concept:
The full solution is non-trivial and its development would likely take several months.
Edit note: why is this challenging for font renderers? Ligatures, in general, were aesthetic devices such that characters that otherwise clash; it replaces two glyphs with a new one. Note that it is not possible to color only the f in the new fi ligature glyph: it is one shape.
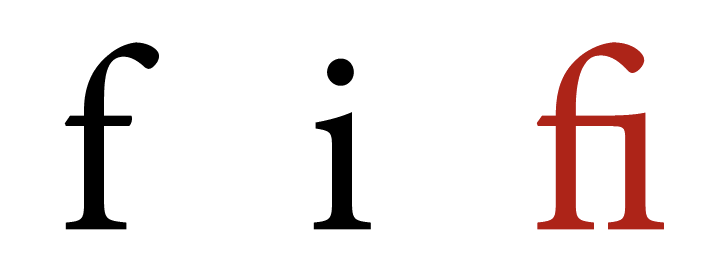
Font shaping and rendering is hard. Not only does it need to take care of global scripts (which are not all conceptually linear), but it must also be extremely performant to the extent that potato computers still should be able to render thousands of characters 30 times a second.
Many shaper-renderers thus make their jobs easier by first breaking apart by script (e.g., Arabic) and language (e.g., Urdu). The assumption is that if they are two different languages/scripts, there must be no interactions between them. This is not a bad assumption.
However, Cantonese Font — in particularly the .jyutping notation — breaks this assumption. When we type 褸.lau5, we are actually providing it with a sequence of mixed Chinese and Latin characters. The font shapers that assumed no interactions between languages — like that used in LibreOffice — will start the rendering process by breaking 褸.lau5 into Chinese 褸 and Latin .lau5 and render them one after another. The rule I wrote for 褸.lau5 thus never gets triggered.