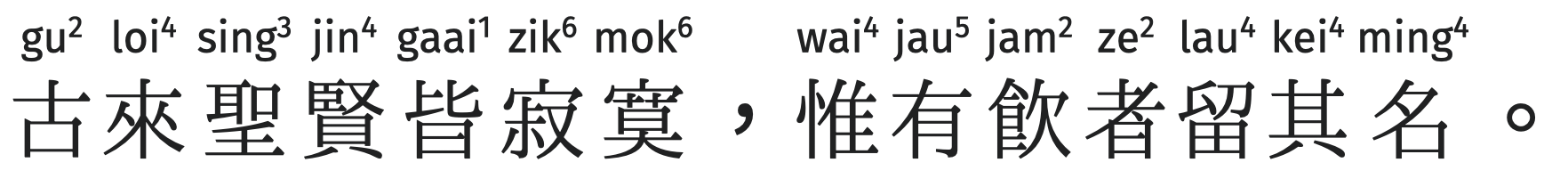2.6 (2024-03-25)
This version sees little changes from most users’ perspective, but has undergone major house-keeping and bug fixes. Notably:
- Perfected pragmatic fixed width effect,
- Perfected
No Jyutping shared metric with Regular/Bold varieties,
- Keyboard shortcut available for the perfect metric No Jyutping
- Cleaning up zero-width non-joiner,
- Bodies for phantom glyphs,
- (experimental) Private User Area codes (
UE000 onwards) for Regular.
For users, there is a new Only Jyutping variant, for a total of six available variants (available to the Lab program supporters).
Pragmatic Fixed Width Effect
2.5 distinguishes between four classes with different widths, and kerns this cross of 4 x 4 = 16 with different widths. Within each class, the characters may be up to 15% wider.
2.6 keeps the fixed width for the 93% of “narrow” characters (36,631 / 39,424) but fits individual widths for the remaining 2,793 characters. These “wide” characters thus takes up only as much space as is necessary for itself.
All-in-all this is a very interesting and important solve to the “ugly Jyutping-annotated text” problem that I’ve been chasing down for two years, and I’ve started a blog post on its evolution. From the user’s perspective… it just looks nice, natural, and rhythm-preserving. “Do nothing” is hard.
No Jyutping
The No Jyutping variant had been very difficult to get right. It is technically a different kind of font (monochrome, not OT-SVG), and must perfectly match the metrics of layers in other fonts, one of which is an SVG layer in which there isn’t much metric to extract.
This is now done (dare I say) perfectly; the Jyutping can seemingly be toggled with keyboard shortcut of cmd/ctrl-I (this greatly improves the ergonomics), with minimal visual glitching. Note that Chinese characters here are not overlapping over the Jyutping variants; since No Jyutping has no jyutping, all characters are fixed width and creates slight narrowing for the 7% or so “wide” characters.
ZWNJ / phantom bodies / PUA
Microsoft renders some width for the zero-width markers. The zero-width marker paths have thus been removed. It does not seem to regress on CoreText or VectorStyler, but no longer displays a bar on Microsoft renderer.
Phantom bodies were added to ligature glyphs to appease Adobe font renderers. This does not serve the goal; Adobe font renderers performed the first substitution (into the phantom glyph) but fails to apply the second rule out.
Significant work (with help from @k.k) went into trying to make .jyutping override work on Microsoft shapers. This included making three additional set of rules where full-width characters were also accepted, in attempts to help the renderer NOT break the ligature up into separate runs. None of the attempts worked.
On the Regular version, Private Use Area codepoints were assigned for non-default Jyutping glyphs. This allows Windows users, in theory, to pick out a specific glyph from the Character Viewer. PUA are fundamentally problematic and should be avoided if possible; one of the issues here is that the codepoints are version-specific, and may refer to an entirely different character in future versions. It is far, far better to simply label with .jyutping (even though the ligature doesn’t process), and get a Mac user to Print to PDF for you.
Only Jyutping variant
An Only Jyutping variant had been introduced to the family. This serves teacher/learners that do not wish to be concerned with Chinese glyphs whatsoever, or as a less intimidating entry point to beginning learners.
It is uncanny to dictate Cantonese and get only Jyutping back out. And then to switch font variant and have the Chinese text appear magically.
Development
-
AWong had completed a jieba-rs binding to Elixir, and I have prepared Yue-specific dictionaries for their use. The weighings have yet to be tuned, but this is generating performant, concurrent-possible segmentation with reasonable accuracy (approximates human segmentation, though not that of an expert human.)
-
I have written the first half of the tooling to take some text, and convert it to a Json with correct Jyutping consistent with how the font behaves. We are close to non-font custom applications that achieves parity with the font.
 insert CJK punctuations into base (2024-02-07)
insert CJK punctuations into base (2024-02-07)